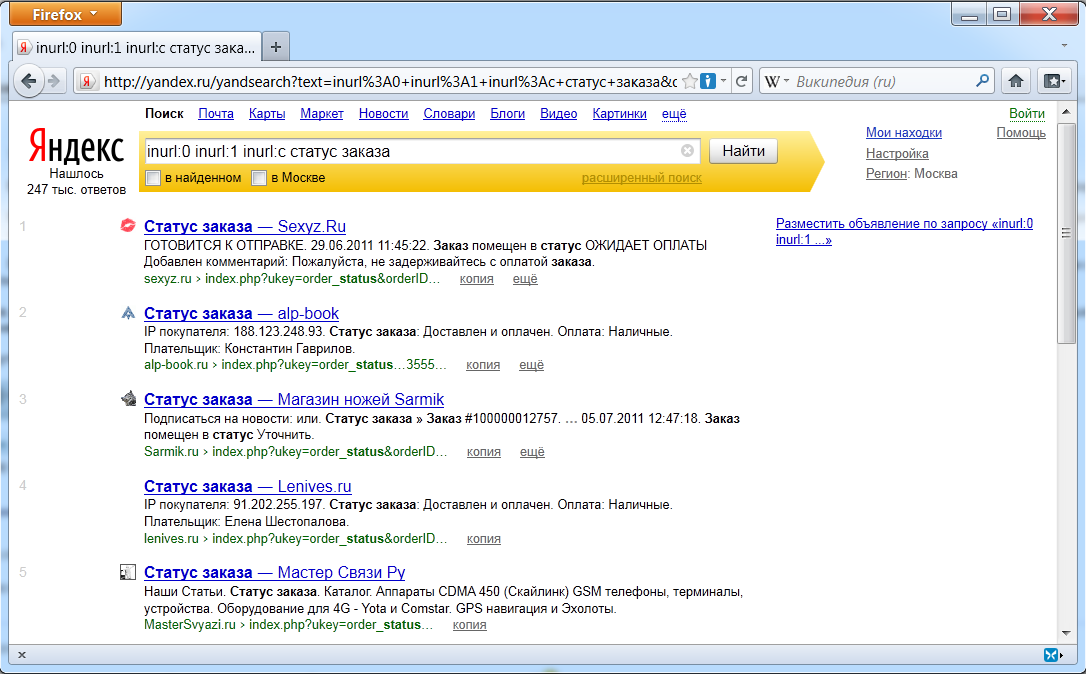
В понедельник стало известно, что с помощью несложного запроса в популярной поисковой системе Яндекс ("inurl:0 inurl:b inurl:1 inurl:c статус заказа") любой желающий может в результатах поиска увидеть статусы заказов, совершённых пользователями в русскоязычных интернет-магазинах, в т.ч. магазинах интимных товаров.
В понедельник стало известно, что с помощью несложного запроса в популярной поисковой системе Яндекс ("inurl:0 inurl:b inurl:1 inurl:c статус заказа") любой желающий может в результатах поиска увидеть статусы заказов, совершённых пользователями в русскоязычных интернет-магазинах, в т.ч. магазинах интимных товаров.
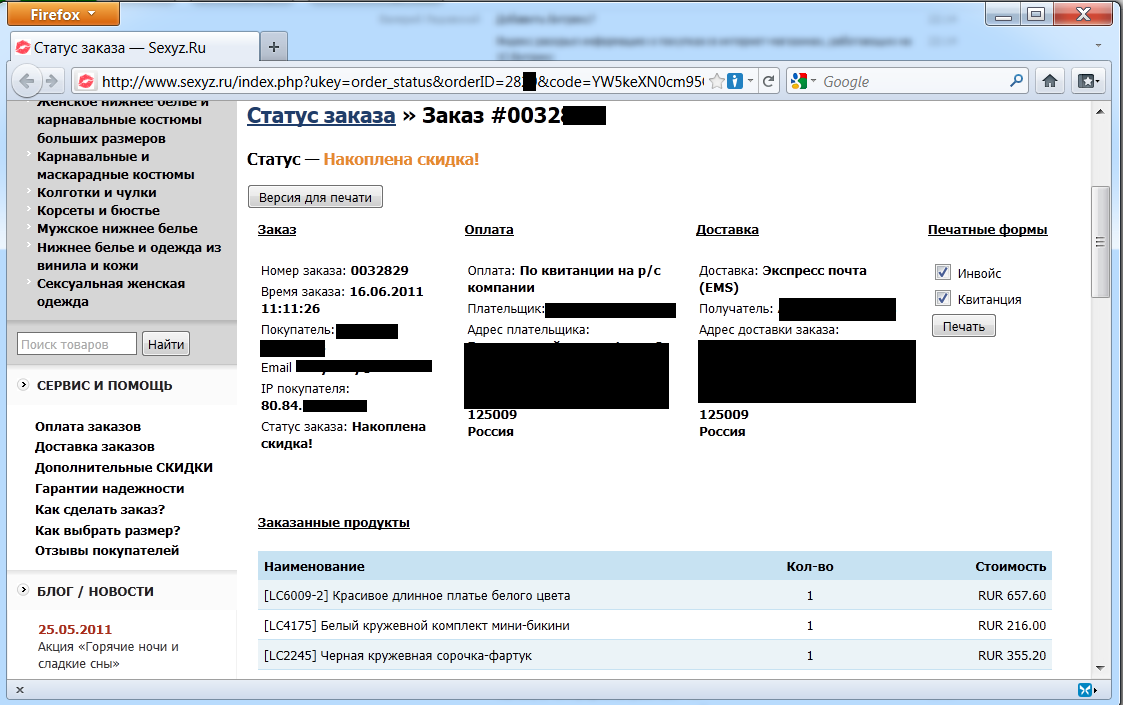
В числе других подробностей можно узнать ФИО покупателя, его адрес, контактные данные, IP-адрес компьютера, с которого регистрировался заказ, а также дату и время совершения заказа. Собственно, ничто не мешает, например, добавить в запрос ФИО любого человека и просмотреть заказы, которые он совершал.
Компания Яндекс, комментируя данную ситуацию, как и в недавнем случае с утечкой текстов СМС-сообщений, отправленных с сайта Мегафона, уповает на неправильное использование владельцами интернет-магазинов файла robots.txt. Хотя известно, что не только правильное использование этих файлов может защитить клиентов интернет-магазинов от утечки приватных данных.
Следует заметить, что в случае с утечкой текстов СМС-сообщений поисковик на "волшебный запрос" выдавал более 8 000 результатов. Новая же утечка куда более серьёзная - поисковик сообщает о 247 000 результатов.
Также интересно, что утечка касается, в первую очередь, русскоязычных магазинов, тогда как при замене слов "статус заказа", например, на "order status", приватной информации о заказах не выдаётся. Это может быть связано как с безответственностью владельцев российских интернет-магазинов, так и с привязкой сервисов компании Яндекс в первую очередь к российским пользователям.
Анализ кода страниц интернет-магазинов, с которых произошла утечка приватных данных, показал, что в этих магазинах используется сервис по построению электронного магазина WebAsyst Shop-Script. Вероятнее всего, причиной того, что подробная информация о заказах попала в Сеть, является уязвимость данного сервиса, который оказался достаточно популярным. Главный офис компании WebAsyst расположен в Москве, из чего следует, что основная часть клиентов компании расположена на территории России. Это может объяснять тот факт, что утечке подверглись данные именно русскоязычных интернет-магазинов.
Стало известно, что для доступа к спискам заказов при использовани WebAsyst Shop-Script не требуется аутентификация, достаточно знать лишь URL, ведущий на подробную информацию о заказе. Вероятно, усугубил ситуацию тот факт, что многие пользователи устанавливают в интернет-браузеры популярные тулбары за авторством поисковых гигантов, которые славятся отправкой информации о действиях пользователя своим авторам. Также следует учитывать тот факт, что, как и в случае с Мегафоном, просочившиеся в Интернет страницы с информацией о заказах доступны постоянно, т.е. не убираются из доступа по прошествии времени.