







Представители Cisco подтвердили, что компания стала жертвой кибератаки операторов программы-вымогателя Yanluowang. Инцидент произошел в конце мая, однако, по словам Cisco, злоумышленники не смогли добраться до внутренней информации и повлиять на работу корпорации.
Несмотря на то что хакерам удалось пробраться в сеть техногиганта, команда безопасности «немедленно приняла меры по сдерживанию и ограничению их доступа».
«Мы не выявили воздействия на наши корпоративные процессы. Продукты и сервисы, а также конфиденциальная информация клиентов и сотрудников не были затронуты в ходе инцидента», — заявили в пресс-службе Cisco.
В блоге корпорации также отмечается, что специалистам удалось установить группировку, стоящую за атакой. Это были операторы программы-вымогателя Yanluowang, утверждающие, что им удалось украсть внутренние данные Cisco.
Злоумышленники даже разместили в даркнете список файлов, которые, предположительно, принадлежат Cisco. Однако в заявлении техногиганта утверждается, что специалистам удалось заблокировать попытки получить доступ к внутренней сети.
Согласно посту команды Cisco Security Incident Response (CSIRT), киберпреступники украли учетные данные одного из сотрудников, получив доступ к его Google-аккаунту. Интересно, что служащий хранил пароли в браузере, за что и поплатился: злоумышленники утащили их при очередной синхронизации.
После атаки операторы Yanluowang направили Cisco скриншот, на котором якобы изображен список скомпрометированных файлов. Как утверждают сами преступники, им удалось укрыть 2,75 ГБ информации.
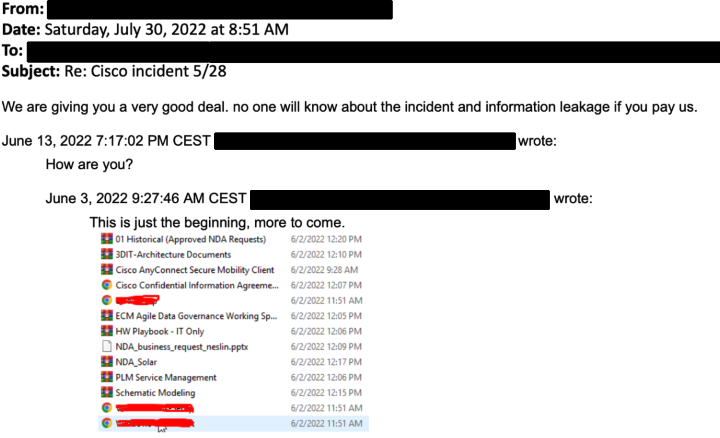
Cisco обратилась в правоохранительные органы, чтобы найти и наказать банду Yanluowang.






