












Чем больше разрешений просит Android-приложение, тем подозрительнее оно выглядит для алгоритма. Правда, резервному копированию, антивирусу или системе родительского контроля доступ к половине смартфона нужен по работе. Но детекторы решили не разбираться и устроили охоту на невиновных.
Исследователи из Сингапурского университета менеджмента и Нанькайского университета проверили шесть популярных детекторов, включая Drebin, MalScan и MaskDroid.
Им скормили 270 безопасных приложений из 49 категорий Google Play, каждое из которых запрашивало не менее девяти опасных разрешений.
Большинство систем записали во вредоносы больше половины выборки. LLM-детектор LAMD разогнал ложные срабатывания до 80%. Если поставить такой фильтр на входе в магазин приложений или корпоративную инфраструктуру, аналитики будут разгребать очередь, почти целиком набитую легальным софтом.
Проблема в старом принципе: детекторы ищут сходство с известными угрозами. Широкий набор разрешений часто встречается у зловредов, но ровно так же выглядят бэкап-сервисы, антивирусы и инструменты управления устройствами. Как сформулировали авторы работы, отклонение — ещё не вредоносность.
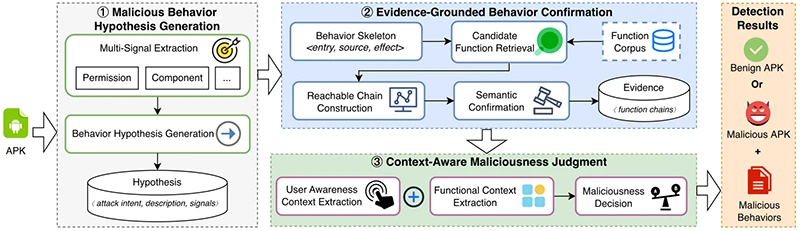
Их система PRAXIS пытается смотреть не только на набор API, но и на контекст. Сначала ИИ предполагает возможную атаку, затем система ищет подтверждающую цепочку вызовов в коде, а после проверяет, соответствует ли поведение назначению приложения и тексту интерфейса.
Такой подход снизил долю ложных тревог на безопасной выборке до 13%, а пропуск вредоносов — примерно до одного из девяти. Однако стоило убрать финальную проверку контекста, как система пропустила 95,3% угроз. Код остался тем же, но без ответа на вопрос «зачем приложение это делает?» защита практически развалилась.
До массового применения PRAXIS тоже далеко: анализ стоит около $0,56 за приложение, а интерфейс и названия функций может подделать сам злоумышленник. Да и 13 ложных тревог на сотню — всё ещё не автоматика, а очередь к живому аналитику.



