





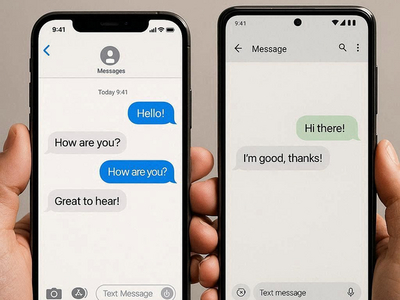
Apple, похоже, делает ещё один шаг к полноценной защите RCS-переписки между iPhone и Android — но, как это часто бывает, не без оговорок. В бета-версии iOS 26.3 Beta 2 обнаружены признаки подготовки сквозного шифрования (end-to-end encryption, E2EE) для RCS-сообщений.
Речь идёт о той самой защите, которая давно стала стандартом в современных мессенджерах, но до сих пор отсутствует в переписке между пользователями iPhone и Android.
Информацию обнаружил пользователь X (бывший Twitter) под ником @TiinoX83. Изучая carrier bundles — пакеты настроек операторов связи — он нашёл новый параметр, позволяющий операторам включать шифрование RCS. Судя по коду, Apple готовит механизм, при котором именно оператор будет «давать добро» на использование защищённых RCS-чатов.
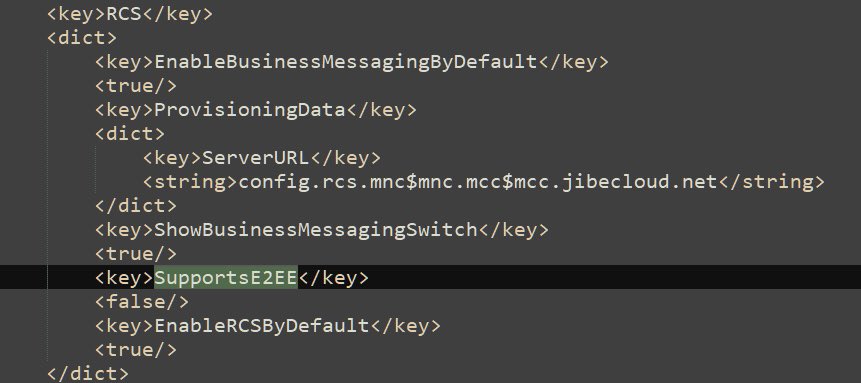
Правда, есть нюанс. На данный момент этот параметр присутствует лишь у четырёх операторов — Bouygues, Orange, SFR и Free, и все они работают во Франции. Более того, ни один из них пока не активировал новую опцию. То есть формально поддержка как бы есть, но по факту она не работает.
История с E2EE для RCS тянется уже не первый месяц. После анонса спецификации Universal Profile 3.0 от GSMA весной прошлого года Apple публично пообещала добавить поддержку защищённых RCS-сообщений в будущих обновлениях iOS. Тогда же стало известно, что шифрование будет строиться на протоколе Messaging Layer Security (MLS) — том самом, который Google уже использует в Google Messages.
Первые намёки на реализацию этой идеи появились ещё в августе, когда в коде iOS 26 нашли следы тестирования MLS. С тех пор ожидания только росли, но реального запуска функции пользователи так и не увидели.






