















Разработчик Дмитрий Виноградов представил утилиту RKN Block Checker с открытым исходным кодом. Она помогает понять, почему конкретный сайт не открывается: это обычная сетевая проблема или блокировка на стороне провайдера / регуляторной инфраструктуры.
Проект написан на Python и опубликован под лицензией MIT. Утилита работает из командной строки и проверяет соединение по цепочке DNS → TCP → TLS → HTTP.
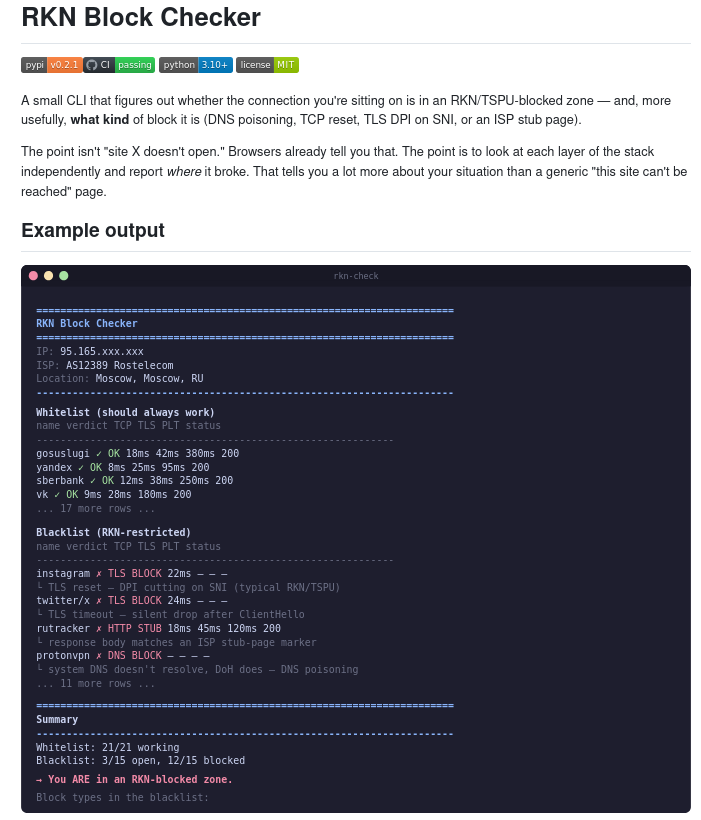
Идея простая: не просто выдать вердикт, что сайт недоступен, а показать, на каком именно уровне всё сломалось. Например, если системный DNS не даёт нормальный ответ, а Cloudflare DoH возвращает корректный адрес, это может указывать на DNS-подмену. Если TCP-соединение на 443-й порт сбрасывается, речь может идти о блокировке на уровне IP.
Если TCP проходит, но соединение рвётся на TLS-рукопожатии с SNI, это уже похоже на работу DPI / ТСПУ. А если сайт открывается, но вместо страницы приходит заглушка провайдера или код 451, утилита фиксирует и такой сценарий.
Автор отдельно подчёркивает, что смысл RKN Block Checker не в том, чтобы заменить браузер. Браузер и так сообщает, что сайт не открылся. Здесь задача другая — разложить проблему по слоям и дать пользователю более понятную картину, где именно произошёл сбой и на что это похоже.
Утилита сравнивает ответы системного DNS и DNS over HTTPS через Cloudflare, проверяет обычное TCP-подключение, запускает TLS-handshake с SNI целевого домена и затем делает HTTP-запрос. Вердикт выставляется по первому уровню, на котором возникла ошибка.

У проекта есть и ограничения. Пока поддерживается только IPv4. Списки целей жёстко заданы в коде и включают около 20 сайтов на категорию, поэтому инструмент не поймает все частные случаи. Кроме того, это разовая проверка без повторов и долгосрочного мониторинга, хотя JSON-вывод можно использовать в cron для регулярных запусков.



