Согласно данным центра мониторинга внешних цифровых угроз Solar AURA, за первые три квартала 2024 года эксперты зафиксировали 569 инцидентов, связанных с утечками данных.
Это на 80% больше, чем за аналогичный период 2023 года и на треть превышает суммарный уровень прошлого года.
Однако эксперты обращают внимание на то, что украденные данные попали в Сеть в частичном или полном объеме лишь в 55% случаев (316 инцидентов).
О части из них можно судить только по фрагментам опубликованных баз, архивов или по отчетам киберпреступных группировок. В статистику также попали данные, которые относятся к 2023 году, но о которых стало известно в 2024 году.
Количество строк скомпрометированных данных год к году увеличилось на 15%, до 800 млн. При этом из статистических данных за 2023 год была исключена утечка, связанная с публикацией 4 млрд строк преимущественно технической информации, которая не является существенно важной с точки зрения кибербезопасности.
Общий объем опубликованных данных, однако, снизился на 95% — до 5 терабайт, что обусловлено уменьшением числа инцидентов, в ходе которых злоумышленники получили доступ глубоко внутрь инфраструктуры компании и смогли добраться до больших массивов неструктурированной информации.
Впрочем, согласно оценкам экспертов, ситуация может измениться: после окончания отчетного периода были отмечены сообщения об успешных кибератаках, в ходе которых в руки злоумышленников попали значительные объемы данных.
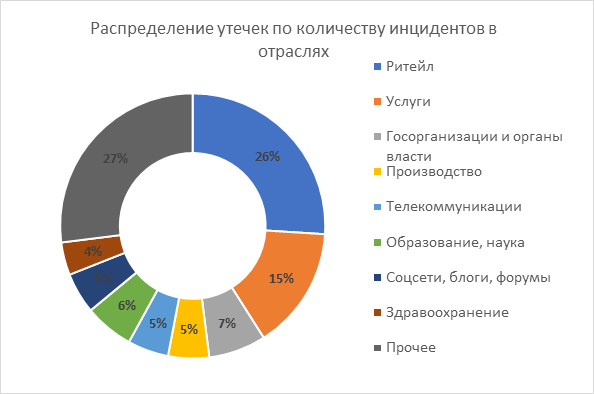
Первое место по количеству инцидентов, связанных с утечками данных, занимает розничная торговля, на этот сектор пришлось 182 утечки. На втором месте сфера услуг (101 инцидент), а на третьем обосновался государственный сектор, включая местные и муниципальные органы власти (45 инцидентов). Далее с минимальным отрывом следует сегмент образования и науки (42 эпизода), а за ним — производственный сектор (38 утечек) и телекоммуникации (37 инцидентов).
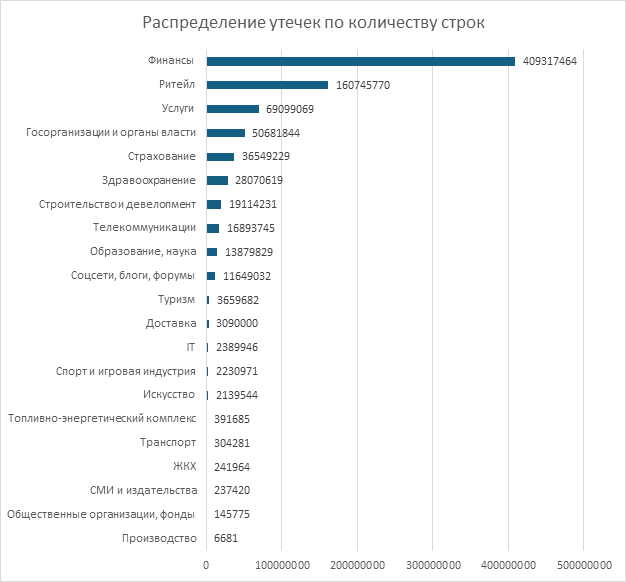
В количественном выражении с большим отрывом первое место занял финансовый сектор.
Данные, полученные в результате утечек, злоумышленники активно используют для проведения фишинговых атак. Количество обнаруженных и заблокированных ресурсов в первые девять месяцев этого года увеличилось по сравнению с аналогичным периодом 2023 года более чем вдвое.
В 2024 году хакеры начали массово использовать фишинговые домены третьего и более глубоких уровней и, как правило, без упоминания брендов, что усложняет поиск таких ресурсов автоматизированными средствами мониторинга.
Если год назад доля таких доменов без связки с брендом составляла 16%, то в 2024 году до 40% фишинговых ресурсов не имеет смысловой связки с брендом. При этом в случае с маркетплейсами доля внебрендовых доменов в этом году достигла 70%.
«Нельзя назвать уменьшение количества строк и объема утекших данных трендом, ведь в любой момент может произойти кибератака, способная привести к утечке миллиардов строк данных. Например, в сентябре 2023 года злоумышленниками была выложена база всего одной компании, содержащая 4 млрд строк с преимущественно технической информацией. Сегодняшняя статистика скорее говорит о том, что утечки данных продолжают оставаться ключевой угрозой для российских организаций, а фишинг переживает свой расцвет. Именно поэтому мы рекомендуем компаниям заниматься обеспечением комплексной защиты от кибератак, которая включает как обучение сотрудников киберграмотности и постоянный поиск внешних цифровых угроз, так и мониторинг внутренней инфраструктуры и внедрение специализированных решений, защищающих от кибератак и предотвращающих утечки», — пояснил Александр Вураско, заместитель директора центра мониторинга внешних цифровых угроз Solar AURA, ГК «Солар».


















