







Злоумышленники могут манипулировать медиафайлами, которыми пользователи обмениваются посредством мессенджеров WhatsApp и Telegram. По словам специалистов Symantec, под угрозой пользователи Android, а причина кроется в том, как операционная система позволяет приложениям получать доступ к файлам во внешнем хранилище.
Как известно, Android-приложения могут хранить файлы как на внутреннем, так и на внешнем накопителе. К файлам во внутреннем хранилище могут получить доступ только приложения-владельцы.
Именно поэтому Google рекомендует разработчикам использовать внутреннее хранилище для данных, которые не должны быть доступны пользователю или другим приложениям.
С другой стороны, мы имеем также внешнее хранилище — файлы на нем могут быть доступны как пользователю, так и другим приложениям. Более того, их также можно модифицировать.
Эксперты антивирусной компании Symantec рассказали о методе, получившем название «Media File Jacking». По сути, он позволяет вредоносному Android-приложению с правами записи во внешнее хранилище видоизменять файлы, пересылаемые через мессенджеры WhatsApp и Telegram.
При этом атакующий, используя этот вектор, может изменить файл после его записи в хранилище, но до того момента, как он загрузиться в интерфейс пользователя.
Атака сработает в случае WhatsApp с настройками по умолчанию и Telegram с включенной функцией «Save to gallery» («Сохранять в галерею»).
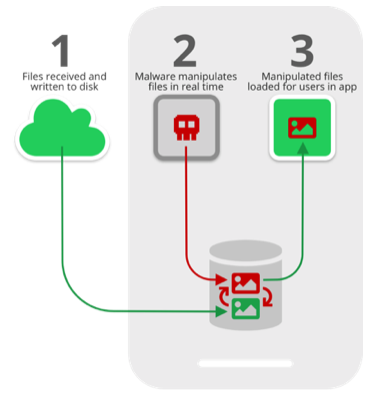
Исследователи Symantec привели в пример модификацию аудиофайлов — злоумышленник может изменить их, а пользователь не будет об этом даже знать. Это особенно опасно в случае передачи с помощью таких файлов реквизитов для оплаты. В результате успешной атаки жертва может отправить киберпреступникам свои деньги.
Symantec также опубликовала несколько видеороликов, в которых демонстрируется вышеописанная атака:






