










Исследователи описали новую технику деанонимизации под названием Adbleed, которая ставит под сомнение привычное ощущение безопасности у пользователей VPN. Проблема кроется в блокировщиках рекламы. Такие расширения, как uBlock Origin, Brave или AdBlock Plus, работают на основе списков фильтров.
Есть базовый список EasyList с десятками тысяч правил для международной рекламы, а есть региональные — для Германии, Франции, России, Бразилии, Японии и других стран.
Они блокируют локальные рекламные домены, и многие пользователи включают их вручную или по рекомендации самого расширения, ориентируясь на язык браузера.
Adbleed использует довольно изящную идею: он измеряет время, за которое браузер обрабатывает запрос к определённому домену. Если домен заблокирован фильтром, запрос обрывается почти мгновенно — за считаные миллисекунды.
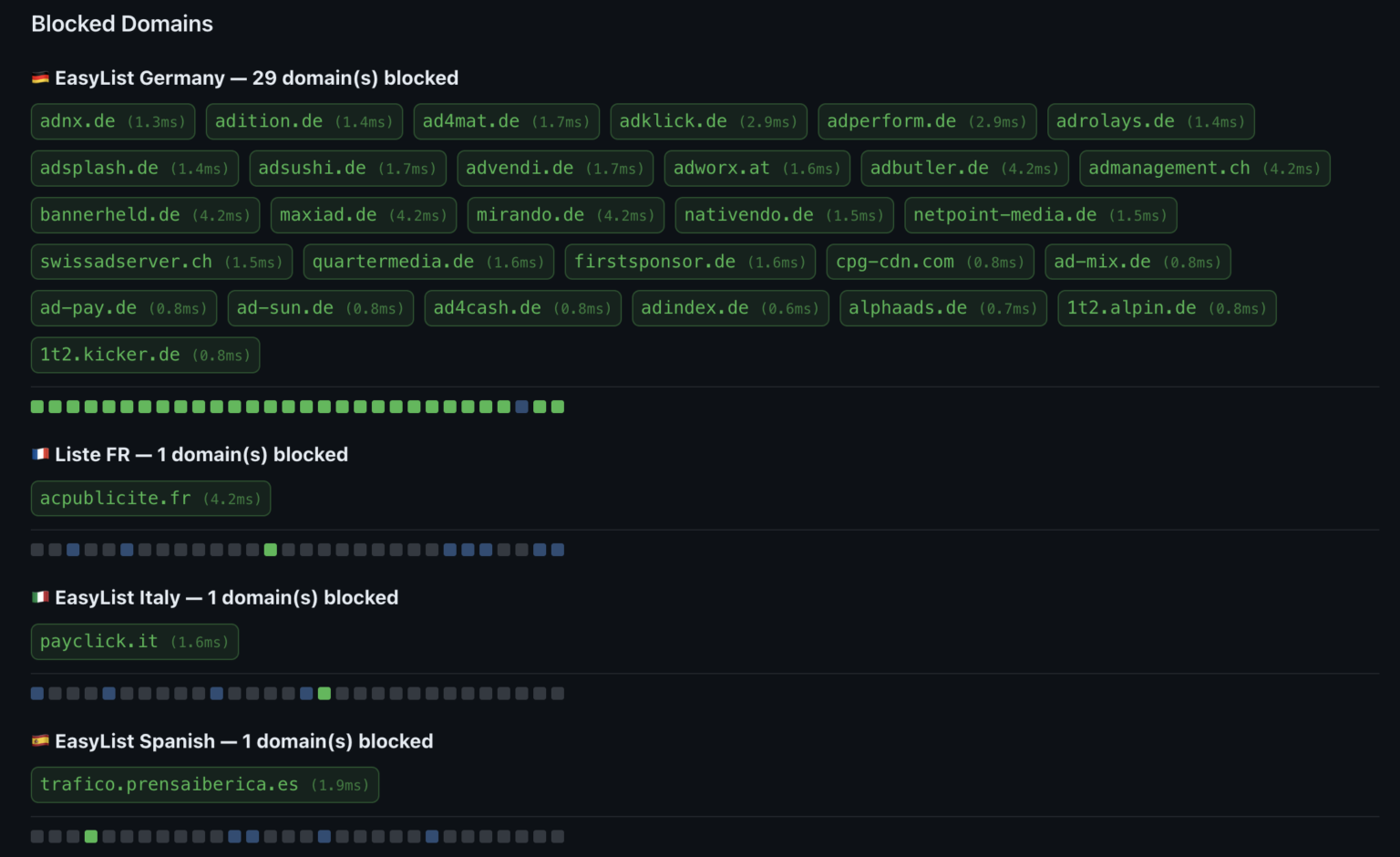
Если не заблокирован, браузер пытается установить сетевое соединение, и даже при ошибке это занимает в разы больше времени. Небольшой JavaScript-скрипт может проверить несколько десятков доменов, характерных для конкретного регионального списка, и по скорости отклика понять, активирован он или нет. Всё это происходит на стороне клиента без cookies, без всплывающих разрешений и без каких-то сложных эксплойтов.
В итоге атакующий может выяснить, какие национальные фильтры включены в вашем браузере. А это почти всегда коррелирует со страной проживания или хотя бы с родным языком пользователя.
Если добавить к этому часовой пояс, параметры экрана и другие элементы цифрового отпечатка, анонимность заметно сужается, даже если вы сидите через VPN или прокси.
Самое неприятное в этой истории то, что VPN тут ни при чём: он меняет сетевую «точку выхода», но не конфигурацию браузера. Ваши фильтры остаются прежними, где бы ни находился сервер.
Пользователю остаётся не самый приятный выбор: отключать региональные списки и мириться с дополнительной рекламой, пытаться «зашумить» профиль случайными фильтрами или принимать риск как есть.



