







Специалисты компании Netcraft выявили поддельный сайт техподдержки eBay. Используя стороннюю службу интерактивного чата от Volusion, кибермошенники пытались выпытать у пользователей eBay учётные данные и другую конфиденциальную информацию.
Агент, оказывавший "техподдержку", утверждал, что пользователи подключались к чату, нажимая соответствующую кнопку в электронном письме (подтверждения заказа), якобы полученном от eBay. После того, как сотрудник Netcraft выразил сомнение относительно легитимности чата, агент немедленно отключился.
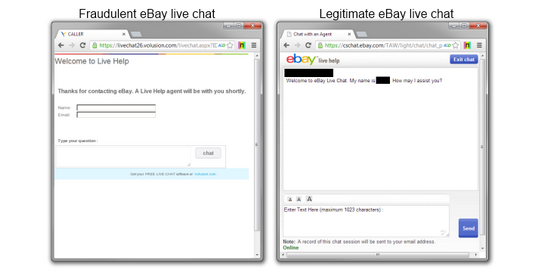
Первоначально окно чата содержало эмблему eBay. Делалось это, вероятно, для большей убедительности, но позже эмблема исчезла. Эксперты полагают, что мошенники, скорее всего, просто сменят эмблему, и продолжат выведывать конфиденциальную информацию у клиентов других компаний.
Эксперты советуют интернет-пользователям быть предельно осторожными, подключаясь к интерактивным чатам. В данном случае опасность усугубляется тем, что киберпреступники используют интерактивный чат Volusion, имеющий легитимные протоколы SSL, что помогает им усыпить бдительность жертвы.
Пользователям советуют подключаться к чатам только на официальных сайтах компаний и не нажимать на подозрительные ссылки, особенно содержащиеся в электронных письмах.






