







Технологии слежения за пользователями интернета развиваются семимильными шагами. Все начиналось с первого поколения идентификаторов, которые использовали серверы, — cookies и evercookie. Затем стали применяться более изощренные тактики второго поколения: вместо установки нового идентификатора они распознают пользователя по версиям установленных плагинов и данным User Agent.
Зачастую техники первого и второго поколений используются вместе для восстановления потерянных файлов cookies. Недостаток как первого, так и второго поколения методов слежения заключается в том, что они осуществляются в рамках лишь одного браузера. Поэтому сейчас в разработке третье поколение технологии слежения — целью его является отслеживание пользователей интернета по нескольким устройствам.
2. Информация, используемая при формировании виртуального отпечатка
За нами следят
Три исследователя из Вашингтонского университета опубликовали под названием «Кросс-браузерное слежение за пользователями интернета с помощью ОС и аппаратных функций». Их идея состоит в том, чтобы идентифицировать конкретных пользователей, используя некоторые особенности операционной системы и аппаратного обеспечения компьютера, например модель видеокарты или процессора. Вместе с аппаратным обеспечением они также предлагают учитывать особенности браузера (плагины, расширения, дополнения).
Эксперты используют JavaScript, который оценивает соответствующие функциональные возможности ОС и аппаратной составляющей, благодаря чему получается добыть аналог отпечатка пальца, только в цифровом виде. На практике получается, что когда пользователь посещает сайт, эти скрипты сравнивают этот аналог отпечатка пальца с уже имеющимися в их базе данных. Многие параметры, учитываемые скриптами, рассчитаны на то, что пользователь может поменять браузер.
Рисунок 1. Схема работы технологии слежения третьего поколения
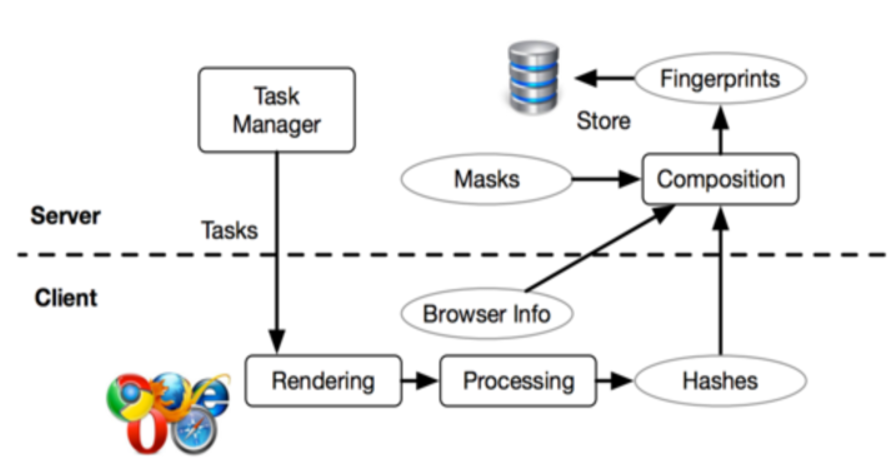
Далее исследователи провели тест, в котором участвовали 3615 виртуальных отпечатков и 1903 пользователя. В результате их метод успешно идентифицировал 99,2% пользователей. В данный момент открытый исходный этой реализации доступен на .
Информация, используемая при формировании виртуального отпечатка
Первым делом в ход идут проверенные методы идентификации пользователей, а затем уже недавно открытые исследователями технологии. Рассмотрим каждый аспект отдельно:
Разрешение экрана – текущее разрешение экрана определяется с помощью объекта screen в JavaScript. В дополнение к этому на помощь могут прийти следующие параметры: availHeight, availWidth, availLeft, availTop и screenOrientation. Все это поможет в формировании виртуального идентификатора пользователя, независимо от того, сколько браузеров он использует. Первые четыре параметра отображают доступные для браузера области дисплея, исключая системные, такие как верхнее меню и панель инструментов macOS. Последний параметр помогает понять, пейзажным или портретным является экран и не перевернут ли он.
Количество виртуальных ядер ЦП – количество ядер можно определить с помощью новой функции браузера под названием hardwareConcurrency, которая предоставляет информацию для Web Workers (средство для запуска скриптов в фоновом потоке). За счет увеличения нагрузки на процессор и доведения его до предела легко определить количество ядер.
Audio Context — AudioContext представляет собой набор функций обработки аудиосигнала, от его генерации до фильтрации с помощью звукового стека в ОС и звуковой карте. Волна в частотной области может отличаться при использовании разных браузеров на одной машине. Однако можно обнаружить, что пиковые значения и соответствующие им частоты относительно стабильны в браузерах. Таким образом, сопоставление пиковых частот и значений помогает при кросс-браузерном слежении.
Линия, кривая и сглаживание — 2D-объекты, поддерживаемые как Canvas (2D-часть), так и WebGL. Сглаживание — это техника компьютерной графики, используемая для уменьшения наложения спектров путем сглаживания неровностей, кривых или ступенчатых линий. Существует множество алгоритмов вроде обработки сигнала или мип-маппинга, с помощью которых можно также идентифицировать пользователя.
Вершинный шейдер — вершинный шейдер отображается графическим процессором и драйвером, может использоваться для видового и перспективного преобразования вершин, для генерации текстурных координат и расчета освещения. В сочетании со следующим пунктом он предоставляет информацию для идентификации пользователя.
Фрагментный или пиксельный шейдер — работает с фрагментами растрового изображения и с текстурами — обрабатывает данные, связанные с пикселями (например, цвет, глубина, текстурные координаты). Пиксельный шейдер используется на последней стадии графического конвейера для формирования фрагмента изображения.
Установленные языки — отображение в браузере определенных языков, например китайского, корейского и арабского, требует установки специальных библиотек. Браузеры не предоставляют API для доступа к списку установленных языков, однако такую информацию можно получить иным способом. В частности, браузер с установленным языковым пакетом будет правильно отображать слова, если же пакет не установлен, вместо слов будут «квадратики». На основе наличия или отсутствия таких «квадратиков» можно идентифицировать того или иного пользователя.
Моделирование и несколько моделей — трехмерное моделирование представляет собой процесс компьютерной графики, математически описывающий объект через трехмерные поверхности. Вершины модели обрабатываются вершинным шейдером, а поверхность — фрагментным. Различные объекты представлены разными моделями и могут взаимодействовать друг с другом, особенно когда существуют такие технологии, как освещение.
Освещение и теневое отображение — освещение представляет собой имитацию световых эффектов в компьютерной графике, а теневое сопоставление проверяет, является ли пиксель видимым при определенном освещении, и добавляет соответствующие тени. Существует много типов освещения, таких как окружающее освещение, направленное освещение и точечное освещение.
Камера — в частности модель, называемая проективной камерой. В WebGL она используется для поворота, увеличения и уменьшения объекта.
Отсечение, или клиппинг — метод оптимизации в рендеринге и компьютерной графике, когда компьютер прорисовывает только ту часть сцены, которая может находиться в поле зрения пользователя. В WebGL отсечения выполняются вершинными и фрагментными шейдерами с дополнительными алгоритмами. Вершинные и фрагментные шейдеры в этом случае опять выдают информацию, с помощью которой можно идентифицировать пользователя.
Выводы
Как можно заметить, большинство новых методов основаны на вершинных и фрагментных шейдерах. Они идеально подходят для снятия виртуальных отпечатков пальцев, потому что на них влияет множество специфических особенностей компьютера.
Если вы хотите точно знать, какие задачи используются для получения этой информации или как сформировать отпечаток пальца из собранной информации, ознакомьтесь с , опубликованным исследователями.




